
简单了解线程池
本文参考
Java线程池实现原理及其在美团业务中的实践 (qq.com)
硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理 | Throwable (throwx.cn)
池化思想
线程池运用了池化的思想,类似的还有连接池、对象池,具有以下的一些好处:
- 减少线程创建、销毁的损耗
- 更快的响应任务请求
- 更好的管理线程以及监控线程
线程池创建方式
Executors
Executors类的四种JDK定义好的线程池:底层还是封装的ThreadPoolExecutor
主要的区别就在于线程数和队列的配置,无论是哪种都会有OOM的风险(线程数过多或者队列的任务过多)
- SingleThreadPool:单实例的线程池
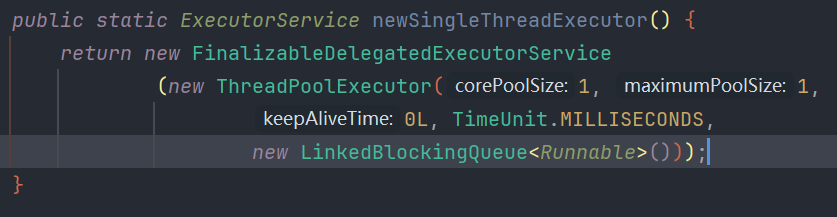
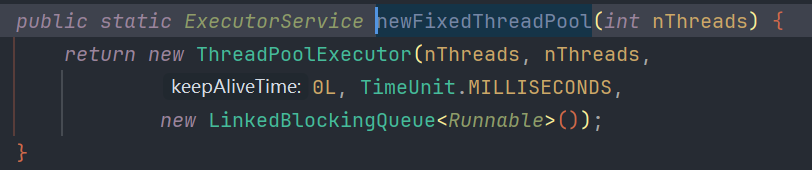
- FixedThreadPool:SingleThreadPool的多线程版本
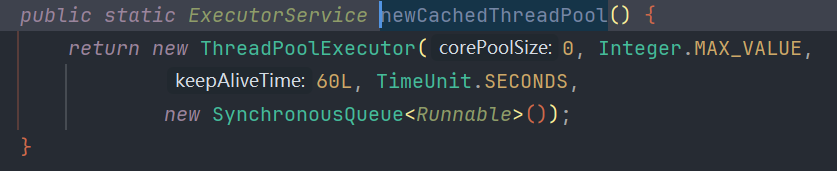
- CachedThreadPool:不能把任务暂存到同步队列
- ScheduledThreadPool:根据任务放入时间先后,存储任务到堆中,不断从堆顶取任务

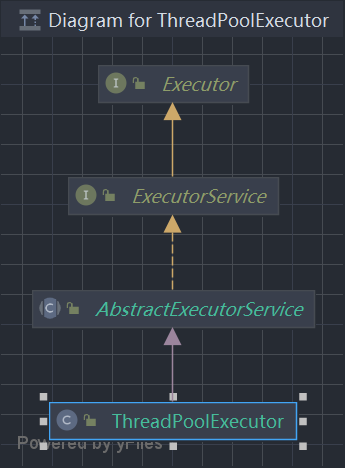
ThreadPoolExecutor
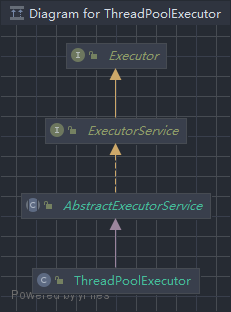
顶层父接口Executor只定义了一个方法execute()用于执行任务,ExecutorService实现了Executor接口,并对它进行拓展,如submit()方法、shutdown()方法等,ThreadPoolExecutor是子类实现,有许多方法都是在ThreadPoolExecutor具体实现的。
七大参数:
- 核心线程数:
- 最大线程数:
- 非核心线程能够空闲的最长时间:
- 时间单位:
- 任务队列:一般为BlockingQueue的子类
- ArrayBlockingQueue:基于数组的先进先出队列,此队列创建时必须指定大小
- LinkedBlockingQueue:基于链表的先进先出队列,如果创建时没有指定此队列大小,则默认为Integer.MAX_VALUE
- SynchronousQueue:这个队列比较特殊,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务
- DelayedWorkQueue:内部是堆的结构,按照延迟的时间长短排序,还有扩容机制(1/2时扩容)
- 线程工厂:
- 任务拒绝策略:抛异常一般是比较重要的任务,需要被感知;丢弃任务的话一般是非核心任务如日志
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
线程池提交任务
有execute()和submit()两种方式提交任务,sunmit()方法有返回值,可以通过Future.get()来获取异步任务的执行结果
1 | <T> Future<T> submit(Callable<T> task); |
1 | void execute(Runnable command); |
深入线程池工作流程
主要关注一下几个方面
- 线程池自身状态
- 任务管理
- 线程管理
线程池自身状态
线程池内部用一个AtomicInteger的变量ctl来维护线程池状态(RunState)和线程数量(WorkCount),类似的也可以用一个Integer保存一个小写字符串中哪些字母出现过。
1 | AtomicInteger ctl = rs(高三位)+ wc(线程数量) |
线程池有5个状态:
- RUNNING:正常运行状态
- SHUTDOWN(温和关机):不接受新的任务,可以处理队列还未处理的任务
- STOP(强制关机):不接受新的任务,也不处理队列的任务,同时中断在执行任务的线程
- TIDYING:所有任务终止,没有工作线程
- TERMINATED:结束
| 状态 | 位图 | 十进制值 | 描述 |
|---|---|---|---|
| RUNNING | 111 | -536870912 | 可以接收新的任务和执行任务队列中的任务 |
| SHUTDOWN | 000 | 0 | 不再接收新的任务,但是会执行任务队列中的任务 |
| STOP | 001 | 536870912 | 不再接收新的任务,也不会执行任务队列中的任务,中断所有执行中的任务 |
| TIDYING | 010 | 1073741824 | 所有任务已经终结,工作线程数为0,过渡到此状态的工作线程会调用钩子方法terminated() |
| TERMINATED | 011 | 1610612736 | 钩子方法terminated()执行完毕 |
任务管理
任务执行流程
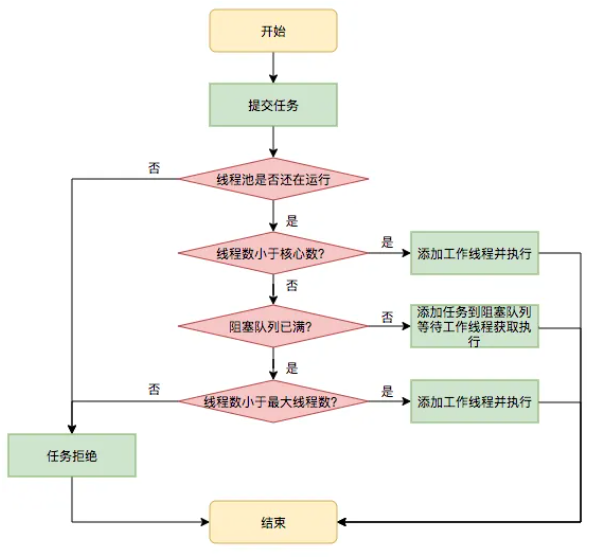
execute()
1 | public void execute(Runnable command) { |
任务缓冲
通过任务队列缓冲解耦任务和线程,实现经典的消费者-生产者模式,当核心线程都在工作,线程池先把任务添加到阻塞队列,当核心线程结束任务,会从阻塞队列拉取新的任务执行。
任务拒绝
当线程池的阻塞队列满了,并且线程数达到最大值,有新任务到来的时候,就会执行相应的拒绝策略,有4种常见的拒绝策略:
- AbortPolicy:抛出RejectedExecutionException异常,默认的策略,当出现问题容易让开发人员知道
- DiscardPolicy:丢弃任务,无异常抛出,适合一些边缘的业务
- DiscardOldestPolicy:丢弃队列中最早的任务,重新提交新任务
- CallerRunsPolicy:交给调用者线程执行,适合让所有任务都执行的情况
线程管理
Worker线程
Worker是ThreadPoolExecutor的一个内部类,继承了AQS并且实现了Runnable接口。
工作线程可以是创建的时候被分配了任务,也可以是空闲的时候通过getTask()去阻塞队列拉取任务。
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable{ |
线程创建
线程池通过addWorker()方法增加线程,需要先判断线程池状态,以及当前线程数,才会新建线程,新建线程的时候可能会给线程分配任务。
addWorker(Runnable firstTask, boolean core)
每个Worker内部持有一个线程,addWorker方法创建了一个Worker工作者,并且放入HashSet的容器中
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
线程回收
线程回收一般是指非核心线程的回收,线程池内部维护了一个线程引用的Hash表,当非核心线程在限定的存活时间内没有获取到新任务,Hash表会删除指向该线程的引用,在GC的时候就会回收该线程。
线程执行
在线程创建启动的时候,会调用Worker重写的run()方法,核心就是下面的runWorker()方法
空闲线程会在一个while循环里面不断地尝试获取队列的任务执行,对于核心线程是不限时的,而对于非核心线程是限时的。
runWorker(Worker w)
1 | final void runWorker(Worker w) { |
getTask()
线程循环获取队列的任务,根据timed决定如何拉取任务,poll()是带超时时间的,take()是阻塞等待
1 | private Runnable getTask() { |
线程池最佳实践
线程池的参数不好配置,特别是线程数要根据不同的场景(CPU密集N+1和IO密集2N)和机器的CPU核心数合理配置。
是否可以有比线程池更好的方案?
是否有可供参考的合理的参数配置方案?
动态化线程池配置
- 关注核心参数:corePoolSize、maximumPoolSize、workQueue,并发性的场景主要是两种:
- 并行执行子任务,提高响应速度。这种情况下,应该使用同步队列;
- 并行执行大批次任务,提升吞吐量。这种情况下,应该使用有界队列,使用队列去缓冲大批量的任务,也要注意核心线程数不能太小,速度会太慢
- 参数可动态修改:通过线程池提供的set方法可以动态修改参数
- 增加线程池监控:当发生了抛出RejectedExecutionException异常,或者是线程数达到了阈值(阈值根据最大线程数设定)